StorPool Release Notes
This section will be used for new features or changes that need a bit more explanation than the usual one-liners at the changelog section.
StorPool Capacity Planner (storpool_capacity_planner)
Short description
The storpool_capacity_planner is a helper tool for planning cluster capacity upgrades. It can be used for all replication and erasure coding schemes.
Why it is needed
Any capacity upgrade calculations done by hand are both difficult and prone to errors at the same time. A single tool is better for providing consistent suggestions for planning capacity upgrades, or suggestions for better placement with a particular erasure coding scheme.
How it works
storpool_capacity_planner gets information for a StorPool cluster either by using the StorPool CLI, or if that is not available, from a provided JSON file.
It then calculates if the cluster can support the following modes: triple replication (3R), EC 2+2 (2+2), EC 4+2 (4+2), EC 8+2 (8+2).
Finally, it prints out the results of the calculation: if the cluster can support the mode as-is, what changes are needed to support it (if any), or if the mode is unsupported completely.
The tool can output a CSV version of the cluster, which can be edited and then fed back to the capacity planner. This enables users to explore new potential storage configurations.
Confirming Supported Modes
Each StorPool mode has requirements on the number of nodes, and their capacity related to other nodes.
Running the tool on an existing cluster can be used to check if (and if not – why) that cluster cannot be used in that specific mode.
The complete documentation for the capacity planner can be found in its user guide: StorPool Capacity Planner.
Initially added with 21.0 revision 21.0.242.e4067e0e4.
Erasure Coding
StorPool introduces a new redundancy mechanism called erasure coding, which can be applied on systems based on NVMe drives.
It can be used as a replacement for the standard replication mechanism offered by StorPool, which would reduce the overhead and the amount of hardware needed for storing data reliably.
Migration to an erasure-coded scheme happens online without interruption in the service and is handled by the StorPool support team for the initial conversion of a running cluster.
For more information on using erasure coding and what advantages it provides, see 14.2. Erasure Coding.
Added with 21.0 revision 21.0.75.1e0880427.
storpool_qos
The storpool_qos service is now used to track and configure storage tier for
all volumes and snapshots based on the updates in their template or a specifically
provided qc tag specifying the required by the orchestration system storage
tier for this volume or snapshot.
A short description and more details on how to configure and usage are available at the user guide article for the service.
Initially added with 20.0 revision 20.0.987.e0aa2a0f7.
Highly available volumecare
Short description
The storpool_volumecare service is now running in highly-available mode
on all nodes in the cluster with the storpool_mgmt service installed, and
will process operations from the currently active management node.
Why it is needed
For the releases until this one, the storpool_volumecare service was
running only on one node in the cluster. In some cases, this resulted in the
service being offline if a whole node went down, until the node returned or the
service was manually migrated to a new node.
This was fine since most clusters rarely change their API nodes, thus the task for keeping the service running on one node somewhere in the cluster was a rare occurrence.
As of 20.0 revision 20.0.466.2a2e26fd9 the storpool_volumecare service
will be automatically installed on all API nodes in the cluster, and will
migrate automatically to the active API node, thus making sure the service is
active at all times.
How it works
The volumecare installation module is no longer available, and the service gets
installed on all nodes running the storpool_mgmt service (API). The service is kept up
automatically on the presently active API node (more on this here).
The migration from the old configuration file is done automatically on the first start of the new version of the service. The existing configuration file will be migrated in the assigned key-value store.
More info on volumecare and the latest changes is available at Volumecare main article.
Initially added with 20.0 revision 20.0.466.2a2e26fd9.
StorPool Log Daemon (storpool_logd)
Short description
The StorPool Log Daemon (storpool_logd) receives log messages from all
StorPool services working in a cluster and the Linux kernel logs for further
analysis and advanced monitoring.
Why it is needed
Tracking the storage service logs for the whole cluster enables more advanced monitoring, as well as safer maintenance operations.
In the long term, it allows for:
Better accountability
Reduced times for investigating issues or incidents
Logs inspection for longer periods
Retroactively detect issues identified in a production cluster in the whole installed base
How it works
The storpool_logd service reads messages from two log streams, enqueues
them into a persistent backend, and sends them to StorPool’s infrastructure.
Once the reception is confirmed, messages are removed from the backend.
The service tries its best to ensure the logs are delivered. Logs can survive
between process and entire node restarts. storpool_logd prioritizes
persisted messages over incoming ones, so new messages will be dropped if the
persistent storage is full.
Typical use cases
Monitoring cluster-wide logs will allow raising alerts on cluster-wide events that are based either on specific messages or classified message frequency thresholds.
The ultimate goal is to lower the risk of accidents and unplanned downtime by proactively detecting issues based on similarities in the observed services behavior.
Specifically, the main usages are to:
Proactively detect abnormal and unexpected messages and raise alerts.
Proactively detect an abnormal rate of messages and raise alerts
Enhance situational awareness by allowing operators to monitor the logs for a whole cluster in one view
Allow for easier tracking of newly discovered failure scenarios
There are relevant configuration sections for the new service if a proxy is required to be able to send data, or if a custom instance is used to override the URL of the default instance procured in StorPool’s infrastructure.
Initially added with 20.0 revision 20.0.372.4cd1679db.
HA Virtual Machine service (storpool_havm)
The storpool_havm service tracks the state of one or more virtual machines
and keeps it active on one of the nodes in the cluster.
The sole purpose of this service is to offload the orchestration responsibility for virtual machines where the fast startup after a failover event is crucial.
A virtual machine is configured on all nodes where the storpool API
(storpool_mgmt service) is running with a predefined VM XML and predefined
volume names. The storpool_havm@<vm_name> service gets enabled on each API
node in the cluster, then starts tracking the state of this virtual machine.
The VM is kept active on the active API node.
In the typical case where the active API changes due to service restart, the VM gets live-migrated to the new active API node.
In case of a failure of the node where the active API was last running, the service takes care to fence the block devices on the old API node and to start the VM on the present active node.
The primary use case is virtual machines for NFS or S3.
Change initially added with 20.0 revision 20.0.19.1a208ffab.
Network interface helper (net_helper)
A new set of tools will assist the setup of network interfaces upon a new installation.
There are many ways to configure a set of network interfaces. The main goal of these tools is to provide an easy way to define an end configuration state, then generate or cleanup/re-generate the network configuration based on this end state kept persistently.
An example initial configuration includes the following:
Physical interfaces to be used for the storage and iSCSI services.
IP networks for both the storage and the iSCSI services.
VLANs for the storage network, additional VLANs for iSCSI and other purposes.
Network topology type for storage/iSCSI, based on known-good pre-defined choices.
This configuration could be used to generate interfaces, and their addresses
based on the provided sp-network, concatenated with the SP_OURID on
each of the nodes and any offset if provided (net_helper genconfig).
Another option is to construct all IP addresses manually, and then apply
with net_helper applyifcfg.
A secondary goal is to provide rapid re-generation of network configurations for all supported operating systems and network configurations we see in production for our internal testing.
There are two ways to provide configuration details:
automatically generate addresses (based on the node’s
SP_OURID):
from ansible to provide necessary parameters for
net_helper genconfigdirectly by using
net_helper genconfigon a nodeby manually constructing a configuration (perhaps based on the provided by
genconfig)by using
net_helper applyifcfgdirectly, and providing all details as arguments.
The primary use case for this instrument is to provide reproducible networking configuration by gluing all internally used tools for configuring the network by exposing all relevant options to the ansible configuration and provide idempotency for networking configuration.
For more details and examples, see 8. Network interfaces.
Change initially added with 19.4 revision 19.01.3061.a03558598.
In-server disk and journal performance tracking
Short description
The server instances now keep an average latency for each drive and its journal if one is configured.
This allows for setting up millisecond-scale hard limit for each disk type (SSD, NVMe, HDD, and any drives with a journal), either globally or on a per-disk/per-journal limit for each drive in a cluster.
The collected average is based on the last window of 128 requests to the drive. The maximum latency is based on the maximum average value recorded for this disk drive from the last time it went up in the cluster.
Why it is needed
The main idea behind this feature is to allow handling RAID controller issues or misbehaving disks generally as well as tracking performance for all drives over time.
How it works
Once the node is upgraded to an enabled version, the collected statistics will start being visible in the analytics platform.
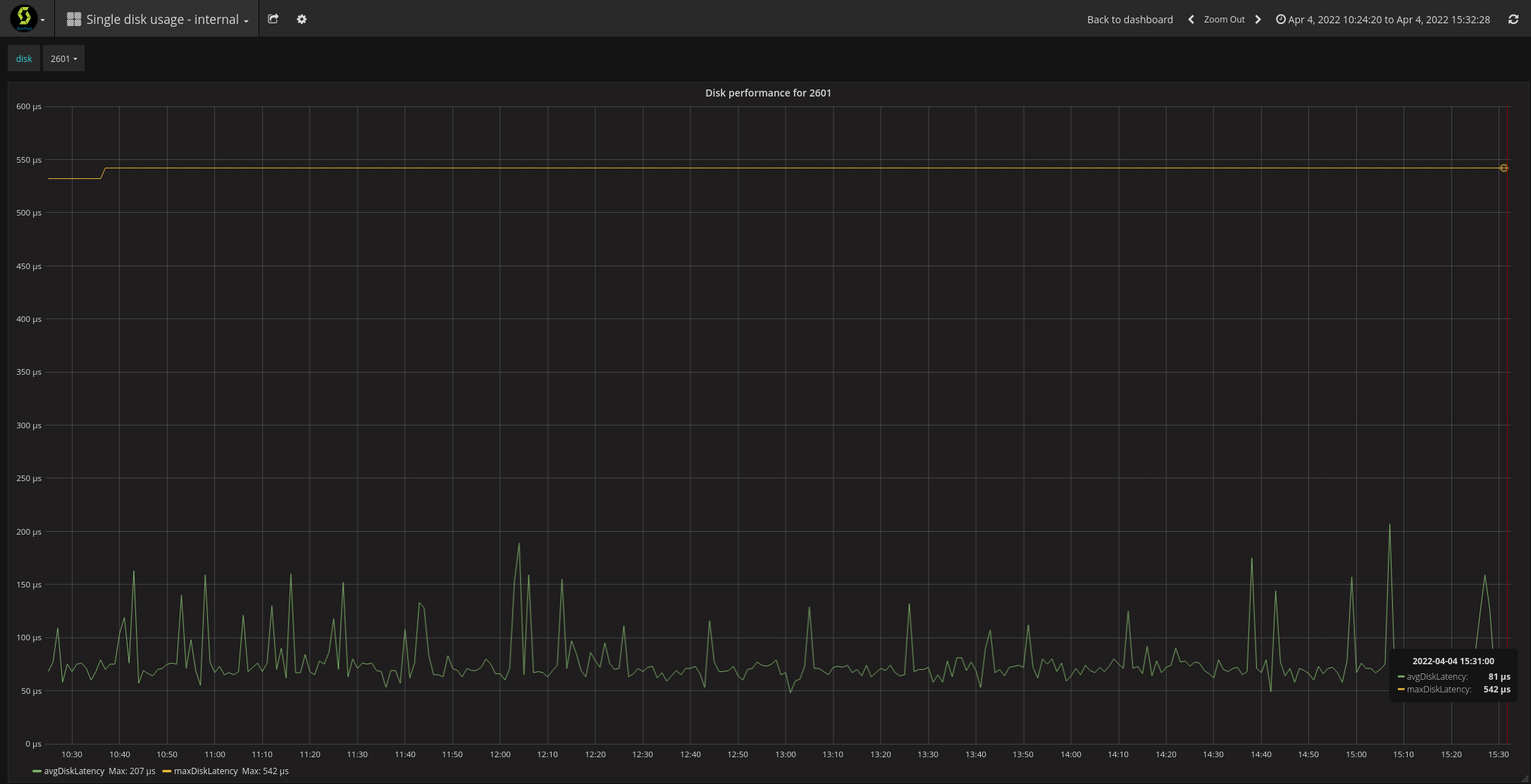
note that for completely idle clusters the average value stays the same as it was for the past 128 requests. Though we rarely see an idle cluster, and all production clusters are running the IO latency monitoring service, that will regularly populate and change the average values.
They could also be viewed from the CLI (See 12.8.4. Disk list performance information for more info)
After a while, there will be enough data to define a threshold for each disk type globally. This threshold usually depends on the use case and the actual workload in the cluster, the drives used, whether a drive is behind a controller with a journal on the controller’s cachevault/battery or on an NVMe device, and probably other factors as well.
More on configuring a global threshold here.
Note
As a safety measure, this mechanism will only work on one node in the cluster. If there is a latency threshold event in another disk or journal while there are already ejected drives, no further drives get ejected from the cluster even if they have latency above the configured thresholds so that the redundancy could never go down to less than two live replicas.
Typical use cases
One example use case is when a battery or a cachevault unit in a RAID controller fails, in which case all writes stop being completed in the controller’s RAM.
In this case, the latency of each of the drives behind this controller gets raised, due to operations completing in the HDDs. The configured threshold is reached, and the server drops the journal for each disk and starts completing writes in the server’s RAM transparently. This immediately raises a monitoring alert that will point to an issue with this controller battery/cache-vault or configuration.
The default behavior of most LSI-based controllers is to flip all cache to write-through mode when some of the disks behind the controller fail. This also leads to abnormal write latency and is handled by the new feature similar to the battery/cachevault issue example above.
As an additional benefit, the maximum thresholds may now be configured for all drives in a cluster globally for each drive type, allowing for a lower impact on user operations when some of the drives misbehave. Currently if a drive stalls, each request hitting it might take up to ten seconds before it is ejected. With this feature, the thresholds may be configured as low as required by the use case and the hardware specification.
As of 19.4 revision 19.01.2930.57ca5627f the disks will be marked for testing and the server will automatically attempt to return them into the cluster in case this was an intermittent failure. The server stops attempting to re-test and return in case there are more than four failures for the past hour.
Lastly, tracking the performance of each disk over time allows for visibility, and when comparing, subtle changes for similar drives in the cluster are required. A latency-sensitive workload might benefit from tighter limits when necessary.
When a drive or a journal is ejected, the server instance keeps the last 128 requests sent to the drive right before it was ejected with detailed info on the last requests it handled.
Change initially added with 19.4 revision 19.01.2877.2ee379917, updated in 19.4 revision 19.01.2930.57ca5627f.
As of 20.0 revision 20.0.93.78df908ec there are new defaults for each disk type that will lessen the impact of a misbehaving disk earlier.
The new defaults are based on aggregated data from thousands of nodes and their drives, and are applied by the StorPool operations team in all clusters.
Per GiB limits
The feature allows specifying per-template or per-volume/per-snapshot IOPS/bandwidth limits relative to the size of the block device. It is implemented as multipliers to the size of the volume in GiB.
This is a usual feature of cloud deployments, thus providing better-matched resources to customers. This will reduce the complexity of the implementations of this feature in the different orchestration systems.
These limits are configurable on per-volume or per-template level. The storage system takes them into account and (re)configures the overall limits of the volume to match the values set per GiB when a new volume is created or when its size changes.
For example a new template called tier3 could be configured with a
fractional limit for IOPS and/or bandwidth:
# storpool template tier3 placeAll hdd placeTail ssd replication 3 iops 1.5 bw 0.12M limitType perGiB
OK
# storpool template list
-----------------------------------------------------------------------------------------------------
| template | size | rdnd. | placeHead | placeAll | placeTail | iops | bw | parent | flags |
-----------------------------------------------------------------------------------------------------
| hybrid | 128 GiB | 3 | hdd | hdd | ssd | - | - | | |
| tier3 | - | 3 | hdd | hdd | ssd | 1.5 | 123 KiB | | G |
-----------------------------------------------------------------------------------------------------
Flags:
R - allow placing two disks within a replication chain onto the same server
G - limits are per GiB, actual limits will be visualized for each volume/snapshot depending on its size
A 1TiB volume will end up with an IOPS/bandwidth limit like this:
# storpool volume data size 1T template tier3
OK
# storpool volume list
---------------------------------------------------------------------------------------------------------------------
| volume | size | rdnd. | placeHead | placeAll | placeTail | iops | bw | parent | template | flags | tags |
---------------------------------------------------------------------------------------------------------------------
| data | 1.0 TiB | 3 | hdd | hdd | ssd | 1536 | 123 MiB | | tier3 | G | |
---------------------------------------------------------------------------------------------------------------------
Flags:
R - allow placing two disks within a replication chain onto the same server
t - volume move target. Waiting for the move to finish
G - IOPS and bandwidth limits are per GiB and depend on volume/snapshot size
The main use case is the ability to provide limited services on a single storage pool. For example for providing faster and slower storage tiers on a flash-only underlying storage without the need for actual hard drives in a cluster.
Change initially added with 19.4 revision 19.01.2686.1f4cf6e1d.
Local and remote recovery overrides
The SP_NORMAL_RECOVERY_PARALLEL_REQUESTS_PER_DISK and
SP_REMOTE_RECOVERY_PARALLEL_REQUESTS_PER_DISK configuration options are now
deprecated, and the same options could now be configured from the CLI (the
defaults are kept at 1 for local and 2 for remote).
With this change, it will be much easier to change the local and remote recovery globally for all disks in the cluster, and to apply overrides for each disk from the CLI.
To configure a new default globally for all disks use:
StorPool> mgmtConfig maxLocalRecoveryRequests 1
OK
StorPool> mgmtConfig maxRemoteRecoveryRequests 2
OK
An override for these options could be configured per disk (more details here), as well with:
StorPool> disk 1111 maxRecoveryRequestsOverride local 1
OK
StorPool> disk 1111 maxRecoveryRequestsOverride remote 2
OK
Or cleared so that the defaults in mgmtConfig take precedence:
StorPool> disk 1111 maxRecoveryRequestsOverride local clear
OK
StorPool> disk 1111 maxRecoveryRequestsOverride remote clear
OK
An example use case would be the need to speed up or slow down a re-balancing or a remote transfer, based on the operational requirements at the time - i.e., lower the impact on latency-sensitive user operations or decrease the time required for getting a cluster back to full redundancy, or a remote transfer completed faster.
Disk discovery and initialize helper
A new disk_init_helper set of tools will assist the setup with the
initialization of NVMes, SSDs, PMEMs, and HDDs as StorPool data drives.
For detailed usage and examples, see 7. Storage devices.
Persistent memory support
Journaling for hard-disks is now supported on persistent-memory devices (for example, Intel Optane Persistent Memory 200 Series ).
Persistent memory devices are fast enough and provide a reasonable guarantee for power-loss protection to be usable for journaling (persisting) and completing operations quickly without waiting for a confirmation from the underlying hard disk. Until now, the options available were either the power-loss protected cache of a RAID controller (which had its own set of problems), or a NVMe device.
It’s used by creating partitions on a pmem namespace, created with ndctl.
The usage is as follows:
create a namespace with
ndctl create-namespace. The size should be as large as to fit the number of needed 100MiB journals;in the namespace, create partitions, 100MiB for each journal, aligned on 1MiB boundaries;
for each hard disk being initialized, pass on the
/dev/pmem...device as a journal.
Appears with 19.3 revision 19.01.2539.30ba167e1 release.
Meta V2 release
The internal metadata structure is updated for more efficient metadata operations.
The upgrade will provide:
significantly improved flexibility for clusters with a large number of volumes/snapshots and chains of volumes or snapshots with sizes larger than 1TiB.
better overall relocator performance;
more efficient object use for large snapshots;
improved overall snapshot delete cycle;
StorPool support team handles the upgrade to meta V2. The upgrade is in the internal data structures and will be enabled once all services in the cluster are running the latest version.
Once upgraded, the size of the disks sets table can be updated for each volume (or snapshot) to up to 32K. For example, a very large volume filled with data can be updated to a larger disk sets table size, providing more granularity when re-balancing its data. This set of features will be very helpful when a cluster has a small set of disks (the usual for a backup only cluster) or disks with different sizes, typical for clusters in process of expansion or hardware being upgraded/replaced.
Note
Note that expansions of the volume/snapshot disk table with a larger size will require a re-balancing operation, though shrinking will be applied immediately by the relocator.
There are few small changes in the output for some commands after the upgrade
to meta V2 is completed, for example, the storpool task list command output
will now flag all operations related to a change in the volume or snapshot
policy with balancer (example output in 12.19. Tasks).
Appears with 19.3 revision 19.01.2401.48d842f1d release.
The storpool_ctl helper tool
The storpool_ctl is a helper tool providing an easy way to perform an
action for all installed services on a StorPool node. An example action is
to start, stop, restart them, or enable/disable them on boot. Other such actions
might be added later so that they could benefit from the additional safety
checks already added in the present tool.
Different nodes might have different sets of services installed, depending on the environment, or whether the node is client, a server, converged node (both) or if services are added or removed.
An action could be executed with a simple storpool_ctl <action>.
Presently supported actions are:
# storpool_ctl --help
usage: storpool_ctl [-h] {disable,start,status,stop,restart,enable} ...
[snip]
The set of services reported by the tool matches the ones that will be reported by the monitoring system.
Another typical use case is when all services needs to be started and enabled. These usually happen right after a new installation. Or the opposite case when all services have to be disabled/stopped when a node is being uninstalled or moved to a different location.
Another example would be when a client-only node is promoted to a server (often referred to as a converged node). In this case after initializing all the drives on this node the tool will take care to start/enable all required additional services.
A typical use case is querying for the status of all services installed on this node. For more usage scenarios and examples, see 10. Managing services with storpool_ctl.
Initially added with 19.2 revision 19.01.1991.f5ec6de23 release.
Initiator addresses cache for storpool_stat
The storpool_stat service will now track and will raise an alert for all
unreachable initiator addresses in each portal group that have at least one
export and have connected to some of the portals at least once.
The idea is to continue tracking the connectivity to the initiators regardless of the presense of a live session.
With this change the monitoring system will better detect obscure networking issues.
The service tracks initiator addresses for each portal group until they have no exports in the portal group or alternatively until they are deleted from the cluster configuration.
This change is relevant for all clusters configured to export targets through iSCSI.
The cluster have to be configured with a kernel-visible address for each portal
group in the cluster configuration on each of the nodes running the
storpool_iscsi service
(related change for adding interfaces).
Initially added with 19.2 revision 19.01.1946.0b0b05206 release.
Remote bridge status
New functionality added in CLI and API now shows the state of all registered bridges to clusters in other locations or sub-clusters in the same location.
Sometimes connectivity issues might lead to slower bridge throughput and to occasional errors, which could now be tracked. We are planning to add an additional dashboard in analytics.storpool.com for the statistics collected from the bridge in the future so that periods with lower throughput could be correlated to other events when investigating for connectivity problem or when measuring throughput performance between clusters, bottlenecks when moving workloads between sub-clusters in a multicluster and others.
The new functionality is available in the CLI and the API (of which the CLI is just a frontend of). Now showing:
The state of the remote bridge (idle, connected)
- The TCP state of the configured remote bridges
Connection time
TCP errors
Time of the last error
Bytes Sent/Received
Additional TCP info (available from API only)
Number of exports from the remote side
Number of sent exports from the local side
Example output from the CLI is available in the CLI section in the user guide.
Initially added with 19.2 revision 19.01.1813.f4697d8c2 release.
vfio-pci driver handling for NVMe devices
The storpool_nvmed service now may optionally handle NVMe drives through
the vfio-pci driver.
This option will provide better NVMe drives compatibility on some platforms, as
the vfio-pci driver is widely used.
The storpool_nvmed could now optionally bind NVMe drives to the vfio-pci
driver instead of the currently default storpool_pci one (with the
SP_NVME_PCI_DRIVER=vfio-pci configuration option).
The main reason this is not the new default is that the
iommu=pt option is required for both Intel and AMD CPUs and the
intel_iommu=on option additionally for Intel CPUs only on the kernel
command line, thus this might require setting up some parameters in existing
clusters.
Note
A new tool is available for auto-detecting the CPU and fixing the grub
configuration accordingly at /usr/lib/storpool/enable_grub_iommu.
The vfio-pci driver will become the new default for newly
validated devices with present production installations gradually moving towards
it as well.
You can read more about NVMe drives configuration at 6.7.2. NVMe SSD drives.
Initially added with 19.2 revision 19.01.1795.5b374e835 release.
Auto-interface configuration
The iface-genconf instrument is now extended to cover complementary iSCSI
configuration as well.
The main reason for the extension is a planned change in the monitoring system
to periodically check if the portal group and portal addresses exposed by the
storpool_iscsi controller services are still reachable. This change will
require adding OS/kernel interfaces for each of the portal groups, so that they
could be used as a source IP endpoint for the periodic monitoring checks.
The iface-genconf is now accepting an additional --iscsicfg option in
the form of:
VLAN,NET0_IP/NET0_PREFIX- for single network portal groupsVLAN_NET0,NET0_IP/NET0_PREFIX:VLAN_NET1,NET1_IP/NET1_PREFIX- for multipath portal groups
The additional option is available only with --auto so the usage is assumed
as complementary to the interface configurations initially created with the same
tool and is required to auto-detect configurations where the interfaces
for the storage system and the iSCSI are overlapping.
An example of adding an additional single portal group with VLAN 100 and portal
group address 10.1.100.251/24 would look like this:
iface-genconf -a --noop --iscsicfg 100,10.1.100.251/24
The above will auto-detect the operating system, the type of interface
configuration used for the storage system and iSCSI, and depending on the
configuration type (i.e. exclusive interfaces or a bond) will print
interface configuration on the console. Without the -noop option
non-existing interface configurations will be created and ones that already exist will not be
automatically replaced (unless iface-genconf is instructed to).
The IP addresses for each of the nodes are derived by the SP_OURID
and could be adjusted with the --iscsi-ip-offset option that will be
summed to the SP_OURID when constructing the IP address.
The most common case for single network portal group configuration is either
with an active-backup or LACP bond configured on top of the interfaces
configured as SP_ISCSI_IFACE.
For example with SP_ISCSI_IFACE=ens2,bond0;ens3,bond0 the additional
interface will be bond0.100 with IP of 10.1.100.1 for the node with
SP_OURID=1, etc.
The same example for a multipath portal group with VLAN 201 for the first network and 202 for the second:
iface-genconf -a --noop --iscsicfg 201,10.2.1.251/24:202,10.2.2.251/24
In case of exclusive interfaces (ex. SP_ISCSI_IFACE=ens2:ens3) or in case
of an active-backup bond configuration (ex. SP_ISCSI_IFACE=ens2,bond0:ens3,bond0)
the interfaces will be configured on top of each of the underlying interfaces
accordingly:
ens2.201with IP10.2.1.1ens2.202with IP10.2.2.1
The example is assumed for a controller node with SP_OURID=1.
In case of an LACP bond (i.e. SP_ISCSI_IFACE=ens2,bond0:ens3,bond0:[lacp])
all VLAN interfaces will be configured on top of the bond interface (example
bond0.201 and bond0.202 with the same addresses), but such peculiar
configurations should be rare.
The --iscsicfg could be provided multiple times for multiple portal group
configurations.
All configuration options available with iface-genconf --help, some examples
could be seen at https://github.com/storpool/ansible
Initially added with 19.1 revision 19.01.1548.00e5a5633 release.
Volume overrides
Note
Presently overrides are manually added by StorPool support only in places that require them, at a later point they will be re-created periodically so that new volume objects are included in this analysis regularly.
Volume disk set overrides (or in short just volume overrides) refer to changing the target disk sets for particular object IDs of a volume with different disks than the ones inherited from a parent snapshot or created by the allocator.
This feature is useful when many volumes are created from the same parent snapshot, which is the usual case when a virtual machine template is used to create many virtual machines ending up with the same OS root disk type. These are usually the same OS and filesystem type, as well as behaviour. In the common case the filesystem journal will be overwritten on the same block device offset for all such volumes. For example a cron job running on all such virtual machines at the same time (i.e. unattended upgrade) will lead to writes to this same exact object or set of objects with the same couple of disks in the cluster ending up processing all these writes. This ends up causing an excessive load on this set of disks in the cluster which will lead to degraded performance when these drives start to aggregate all the overwritten data or just from the extra load.
A set of tools could now be used to collect metadata for all objects from each of the disks from the API and analyze which objects are with the most excessive number of writes in the cluster. These tools will calculate proper overrides for such objects so that even in case of an excessive load on these particular offsets on all volumes created out of the same parent, they will end up on different sets of disks instead of the ones inherited from the parent snapshot in the original virtual machine template.
The way the tooling is designed to work is by looking for a template called
overrides which placeTail parameter is used as a target placement group
for the disks used as replacement for the most overwritten objects. For example
if a cluster has one template with hybrid placement (i.e. one or more replicas
on HDDs and tail on SSD or NVMe drives) an override would have to be the SSD or
NVME placement group. An example:
-------------------------------------------------------------------------------------------------
| template | size | rdnd. | placeHead | placeAll | placeTail | iops | bw | parent | flags |
-------------------------------------------------------------------------------------------------
| hybrid | - | 3 | hdd | hdd | ssd | - | - | | |
| overrides | - | - | default | default | ssd | - | - | | |
-------------------------------------------------------------------------------------------------
Multiple templates will use the same overrides template placeTail specification.
An example would be an SSD only and HDD-only template in which case the drives
for the top most overwritten objects will be overridden with SSD disks.
The tool to collect and compute overrides is
/usr/lib/storpool/collect_override_data, and the resulting overrides.json
file could be loaded with:
# storpool balancer override add-from-file ./overrides.json # to load
# storpool balancer disks # to see how the data will be re-distributed
# storpool balancer commit # to actually load them for redistribution
Note that once overrides are loaded on future re-balancing operations the overrides will be re-calculated (more details on balancer - 18. Rebalancing the cluster).
Note
As of 19.3 revision 19.01.2268.656ce3b10 loaded overrides are visible with
storpool balancer disks and require a storpool balancer commit to be applied.
The default number of top objects to be overridden is 9600 or 300GiB of virtual space.
This could be specified as the MAX_OBJ_COUNT environment variable to
collect_override_data tool.
First appears with 19.1 revision 19.01.1511.0b533fb release.
In-server disk tester
This feature improves the way storage media and/or controller failures are handled, by automatically trying to return a drive that previously failed an operation back into the cluster in case it is still available and recover from the failure.
On many occasions a disk write (or read) operation might timeout after the drive’s internal failure handling mechanisms kick in. An example is a bad sector on an HDD drive being replaced or a controller to which the drive is connected resets. In some of these occasions the operation times out and an I/O error is returned to StorPool, which triggers an eject for the failed disk drive. This might be an indication for pending failure, but in most cases the disk might continue working without any issues for weeks, sometimes even months before another failure occurs.
With this feature such failures will now be handled by automatically re-testing each such drive if it is still visible to the operating system. If the results from the tests are within expected thresholds the disk is returned back into the cluster.
A disk test can be triggered manually as well. The drive will automatically be returned back into the cluster if the test was successful. The last result from the test can be queried through the CLI.
First appears with 19.1 revision 19.01.1217.1635af7 release.
Reuse server implicit on disk down
This feature allows a volume to be created even if a cluster is on the minimum system requirements of three nodes with a single disk missing from the cluster or if one of the nodes is down at the moment.
Before this change all attempts to create a volume in this state would have resulted in “Not enough servers or fault sets for replication 3” error for volumes with replication 3.
With this feature enabled the volume will be created as if the volume was
created with reuseServer; for details see here.
The only downside is that the volume will have two of its replicas on drives in the same server. When the missing node comes back a re-balancing will be required so that all replicas created on the same server are re-distributed back on all nodes. A new alert will be raised for these occasions, more on the new alert here.
More on how to enable in the CLI tutorial (link to section).
As of 19.3 revision 19.01.2318.10e55fce0 all volumes and snapshots that
violate some placement constraints will be visible in the output of
storpool volume status and storpool volume quickStatus with the flag
C; for details, see 12.10.3. Volume status.
This change will be gradually enabled on all eligible clusters and will be turned on by default for all new installations.
Active requests
StorPool has support for listing the active requests on disks and clients.
With this change this functionality is expanded to be able to get all such
data from other services (for example storpool_bridge and
storpool_iscsi) and to show some extra details. This is also expanded
to be done with a single call for the whole cluster, greatly simplifying
monitoring & debugging.
This feature was developed to replace the latthreshold tool that showed
all requests of clients and disks that were taking more than a set time to
complete. The present implementation gets all required data without the
need for sending a separate API call for each client/disk in the cluster.
Non-blocking NIC initialization
Non-blocking NIC initialization and configuration allows for StorPool services to continue operating normally during hardware reconfigurations or errors (for example link flaps, changing MTU or other NIC properties, adding/removing VFs to enable/disable hardware acceleration, etc.).
This was developed to handle delays from hardware-related reconfiguration or initialization issues, as most NICs require resets, recreation of filters or other tasks which take time for the NIC to process and if just busy-waited would not allow the services to process other requests in the mean time.
The feature works by sending requests to the NIC for specific changes and rechecking their progress periodically, between processing other tasks or when waiting for other events to complete.
Creation/access of volumes based on global IDs
StorPool now can allow the creation of a volume without a name provided, by assigning it a globally unique ID, by which it could be then referred.
Note
Globally-unique in this regard means world-wide global uniqueness, i.e. no two StorPool deployments can generate the same ID.
This feature was developed to handle some race conditions and retry-type cases in orchestration systems in multi-cluster environment, which could lead to duplication and reuse of another volume. By allowing the storage system to ensure the uniqueness of volume identifiers, all these cases are solved.
MultiCluster mode
MultiCluster mode is a new set of features allowing management and interoperations of multiple StorPool clusters, located in the same data-center allowing for much higher scalability and better reliability in large deployments. Instead of creating one big storage cluster with many hosts, the multi-clustering approach adds the flexibility to have multiple purpose-built clusters, each using fewer hosts. The set of features is built as an extension to Multi site (more at 17.2. Multi site) and each location could now have multiple clusters. For a different analogy, a multicluster would relate to multi-site similarly as a single datacenter to a city.
The first new concept is that of an exported volume. Just like snapshots can be
currently exported to another cluster through the bridge, now volumes can be
exported too for all nearby clusters. An exported volume can be attached to any
StorPool client in a target cluster and all read and write operations for that
volume will be forwarded by the storpool_bridge to the cluster where the
volume actually resides (how to export a volume
here)
The second concept is the ability to move volumes and their snapshots between sub-clusters. The volume is moved by snapshotting it in the sub-cluster where it currently resides - i.e. the source sub-cluster, exporting that snapshot and instructing the destination sub-cluster to re-create the volume with that same snapshot as parent. This all happens transparently with a single command. While the volume’s data is being transferred, all read requests targeting data not yet moved to the destination sub-cluster are forwarded through the bridge service to the source sub-cluster. When moving a volume there is an option to also export it back to the source sub-cluster where it came from and updating the attachments there, so that if the volume is attached to a running VM it will not notice the move. More on volume and snapshot move here.
Both features have minimal impact on the user IOs. An exported volume adds a few tens of microseconds delay to the IO operations, and a volume move would usually stall between a few hundred milliseconds up to few seconds. So for everything except for some extremely demanding workloads a volume move would go practically unnoticed.
A target usecase for volume move is live migration of a virtual machine or a container between hosts that are in different sub-clusters in the multicluster. The move to the destination sub-cluster involves also exporting the volume back and attaching it to the host in the source cluster, almost like a normal live migration between hosts in the same cluster. If the migration fails for some reason and will not be retried the volume can be returned back to the original cluster. Its data both in the volume and its snapshots will transparently move back to the source cluster.
The new functionality is implemented only in extensions to the API - there is no change in what all current API calls do.
There are two extensions to allow using these features explained below.
The first one is the ability to execute API commands in another sub-cluster in a multicluster setup, an example is available here.
The second extension is multicluster mode of operation. It is enabled by
specifying -M as a parameter to the storpool CLI command or executing
multiCluster on in interactive mode (example).
This mimics the single cluster operations in a multicluster environment without
placing additional burden on the integration.
For example a multicluster attach volume command will first check if a volume is currently present in the local sub-cluster. If it is, the command proceeds as a normal non-multicluster attach operation. If the volume is not present in this sub-cluster the API will search for the volume in all connected sub-clusters that are part of the multicluster and if it is found will issue a volume move to the local cluster (exporting it back to the source cluster if the volume is attached there) and will then attach the volume locally. The same is in effect for all other volume and snapshot related commands. The idea is that the multicluster mode can be used as a drop-in replacement of the non multicluster mode, having no effect for local volumes. The only difference is that an attach operation must be targeted to the cluster with the target client in it. This is the main reason for the first extensions, so that the integration doesn’t need to connect to the different API endpoints in each cluster to do its job.
Some words on the caveats - The issue in a Multicluster mode is that of naming the volumes. The whole multicluster acts as a single namespace for volume names, however there is no StorPool enforced uniqueness constraint. We thought long and hard on this decision, but decided at the end against enforcing it, as there is no way to guarantee the uniqueness in cases of connectivity or other disruption in communication between clusters without blocking local cluster operations. We believe that having the ability to work with a single cluster in the multicluster in all cases is far more important.
This decision however places the burden of keeping the volume names unique on the integration. There are few ways this can be handled, the first option is to never reuse a volume name, even when retrying a failed operation, or operation that has an unknown status (e.g. timeout). So if the integration can guarantee this, the uniqueness constraint is satisfied.
Another option, that we are in the process of moving all integrations to, is to
use another new feature - instead of providing a name for the volume create
operation, have StorPool assign unique name to it. StorPool already maintains
globally unique identifiers for each volume in existence - the globalId in the
json output. So the new feature is to be able to use the globalId as identifier
for a volume instead of a name and the ability to create a volume without
specifying a name and having StorPool return the unique identifier. This mode
however is a significant change to the way an integration works. For our
integrations we have chosen to move to this mode as they are plugged in a
complex management systems that we can’t guarantee will never reuse a volume
name, for example during a retry of a volume create operation. This also comes
with a new directory - /dev/storpool-byid holding symlinks to the
/dev/sp-X devices but instead of using the volume names as in
/dev/storpool, using the globalIds.
Violating the uniqueness constraint will eventually result in data corruption
for a given volume, so handling it is a must before considering the multicluster
features. A simple example of how data corruption will occur if there are two
volumes with the same name: Let’s assume the volume name in question is test
and we have one volume test in the source sub-cluster A with a VM working
with it and another volume test in the target sub-cluster B. If trying to
migrate the VM from cluster A to cluster B the multicluster volume
attach command will find the wrong volume test already existing in the target
sub-cluster B and simply attach it to the client, so when the VM is migrated
the data in the volume test will be totally different resulting in data
corruption and VM crash.
There are two more considerations, again naming related, but they are not as dangerous - volume move will recreate the volume in the target cluster with a template named as the one in the source cluster. So every cluster in a multicluster must have all the templates created with the same names.
And the last one is that the different clusters in the multicluster should have
the same names in each of the clusters, so that the remote cluster commands can
be executed from any API endpoint with the same effect. Just for completeness
in each cluster the local cluster can also be (and should be) named, so a
storpool cluster cmd NAME will work for it too.